2023. 2. 7. 15:50ㆍ컴퓨터구조
파이프라이닝은 processor에서 instruction을 수행하는 동안 놀고 있는 자원을 효율적으로 쓰기 위한 방식이다.
원래 processor에서는 Fetch 후 decode 하고 명령어에 따라 수행하고 ALU로 보내고 연산 후에 memory로 보내거나 register로 결과를 다시 레지스터로 보내거나 하는 과정을 거친 후에 다음 명령어가 실행되어서 반복되었다. 이런 수행을 다 기다린 후에야 pc를 증가시켜 다음 명령어를 수행할 수 있었는데 이런 비효율성을 해결하기 위해 pipelining을 이용하게 된다.
Processor의 수행 과정을 나눠보면
1. Fetch
2. Decode
3. Depend on Instruction with ALU
4. PC + 4

파이프라이닝은 A명령어가 들어가고 첫번째 수행이 끝나면 B에서 첫번째 수행을 시작하게 된다. Fetch단계에서 1개의 instruction만 들어갈 수 있으므로 B는 대기한다. A가 끝나고 B에서 Fetch에 접근한다. 이런식으로 노는 과정이 없도록 한 것이 파이프라이닝이다.
줄임말 설명
IF : instruction fetch from memory
ID : instruction decode & register read
EX: execute operation or calculate address
MEM: access memory operand
WB: write result back to register
이런 파이프라이닝에서도 위험이 존재한다.
Structure Hazard
Data Hazard
Control Hazard
structure hazard
필요한 resource가 다른 component에 의해 사용되고 있을 때 두 개가 동시에 특정 단계로 가서 이용될 수 없는 문제
리소스가 충돌하는 경우이다. 예를 들어 Memory에서 instruction 메모리와 data memory가 나뉘어 있지 않다면
load/store 명령어를 처리할 때마다 메모리에 접근하여 가져오게 되는데, instruction fetch도 memory에서 작업을 수행하므로 서로 충돌이 나게 된다. 이러한 구조적 이유로 instruction 메모리와 data 메모리를 따로 두게 됐다.

Data hazard
이전에 있던 연산 결과가 필요하는 경우가 있는데 파이프라이닝에서는 접근이 어렵다.
접근하려면 기다렸다가 접근해야한다. 여기서 기다리는 것을 버블이라고 한다.
add $s0, $t0, $t1
sub $t2, $s0, $t3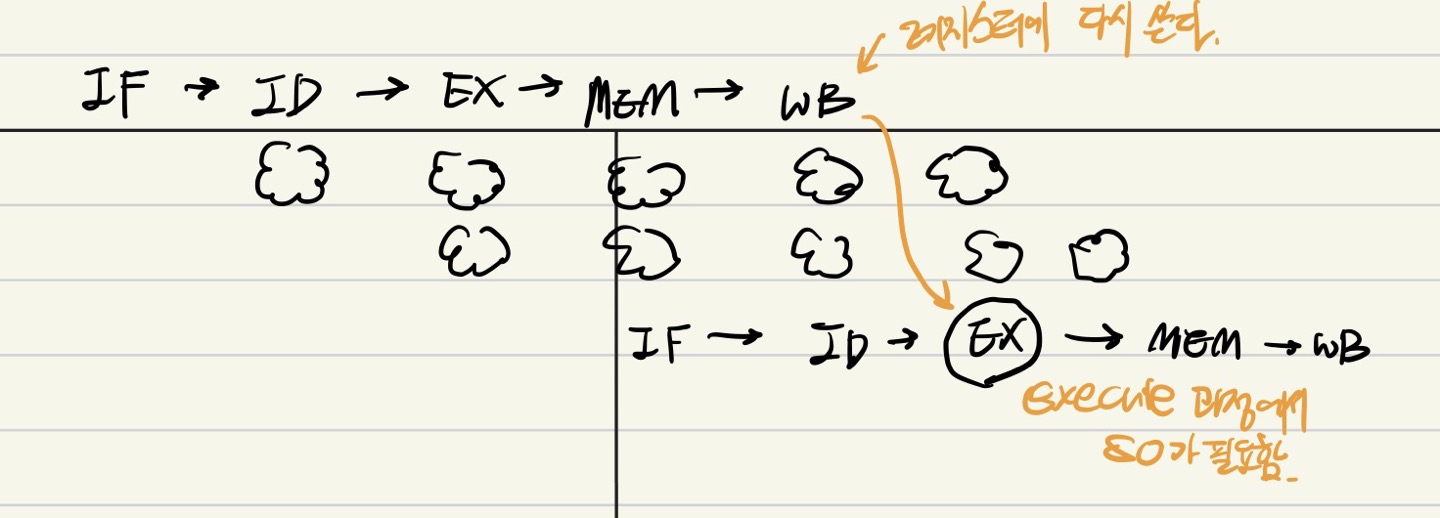
WB단계까지 가는 것이 너무 오래걸리기 때문에 Fowarding 방법을 통해 중간 단계에서도 이 문제를 해결할 수 있다.
Fowarding
ALU를 통해 나온 결과를 data path를 연결해주어서 다음 명령어의 ID -> ALU 로 보내줄 수 있게 한다.
그러면 쉬지 않고도 같은 결과를 낼 수 있다.
Load-Use data hazard
lw 과정의 경우 결과가 memory stage에서 나오게 된다. 그렇게 되면 한 번은 꼭 쉬어야하게 된다.

Code scheduling to avoid stalls
코드의 순서를 잘 맞춰준다면 이러한 버블이 최소한으로 생기게 프로그램이 작동할 수 있게 된다. 이러한 scheduling은 현대 컴파일러가 해주고 있다.
Control Hazard
수행 중에 Instruction의 Condition을 알게 되는 경우에 문제가 생긴다
예를 들어 branch나 jump 명령어의 경우에는 어떤 조건에 따라 점프를 해야하는데 파이프라이닝은 조건에 맞게 하는 것이 아니라 다음 명령어가 계속 수행되고 있으므로 문제가 생긴다. 즉 메모리 낭비가 생긴다.
Fetch 하는 다음 instruction은 branch 결과에 따라 달라지므로 ALU가 끝나고 나서야 알 수 있게 된다. beq if문에서 jump를 안하게 된다면 다행이지만 jump를 하게 되면 stall 버블이 3칸 생겨야한다.
1. decode 하지말았어야 하는 instruction에 대한 문제가 생긴다.
2. 성능 저하
이러한 문제를 해결하기 위해
Branch Prediction
하드웨어적으로 예측하여 뛸지 안뛸지를 예측하고 뛰게되면 어디로 뛸지 예측 되는 곳의 inst를 가져오게 된다.
1. static branch prediction
명령어 수행 이전에 뛸지 안뛸지를 예측하는 방법
2. dynamic branch prediction
명령어 수행동안 기록하면서 특정 패턴을 파악하여 예측하는 방법
'컴퓨터구조' 카테고리의 다른 글
| MIPS processor (0) | 2023.02.07 |
|---|---|
| MIPS representing instruction (0) | 2023.01.15 |
| MIPS-32 ISA 명령어 type (0) | 2023.01.14 |
| MIPS 어셈블리어2 (0) | 2023.01.14 |
| 빅엔디안, 리틀엔디안 (0) | 2023.01.14 |